Class loaded by bootstrap/system class loader. For example, everything from the rt.jar like java.util.*
JNI Local(native code的局部变量)
Local variable in native code, such as user defined JNI code or JVM internal code.
JNI Global(native code的全局变量)
Global variable in native code, such as user defined JNI code or JVM internal code.
Thread Block(JVM虚拟机线程栈)
Object referred to from a currently active thread block.
Thread(状态不是TERMINTED的线程)
A started, but not stopped, thread.
Busy Monitor(被用作锁的对象)
Everything that has called wait() or notify() or that is synchronized. For example, by calling synchronized(Object) or by entering a synchronized method. Static method means class, non-static method means object.
Java Local(局部变量)
Local variable. For example, input parameters or locally created objects of methods that are still in the stack of a thread.
Native Stack(本地方法栈)
In or out parameters in native code, such as user defined JNI code or JVM internal code. This is often the case as many methods have native parts and the objects handled as method parameters become GC roots. For example, parameters used for file/network I/O methods or reflection.
Finalizable(在Finalizable队列中等待的对象)
An object which is in a queue awaiting its finalizer to be run.
Unfinalized(重写了finalize方法,但是还没有被finalize过的对象)
An object which has a finalize method, but has not been finalized and is not yet on the finalizer queue.
Unreachable(像是自定义的根这样的)
An object which is unreachable from any other root, but has been marked as a root by MAT to retain objects which otherwise would not be included in the analysis.
Java Stack Frame(虚拟机栈)
A Java stack frame, holding local variables. Only generated when the dump is parsed with the preference set to treat Java stack frames as objects.
Unknown
An object of unknown root type. Some dumps, such as IBM Portable Heap Dump files, do not have root information. For these dumps the MAT parser marks objects which are have no inbound references or are unreachable from any other root as roots of this type. This ensures that MAT retains all the objects in the dump.
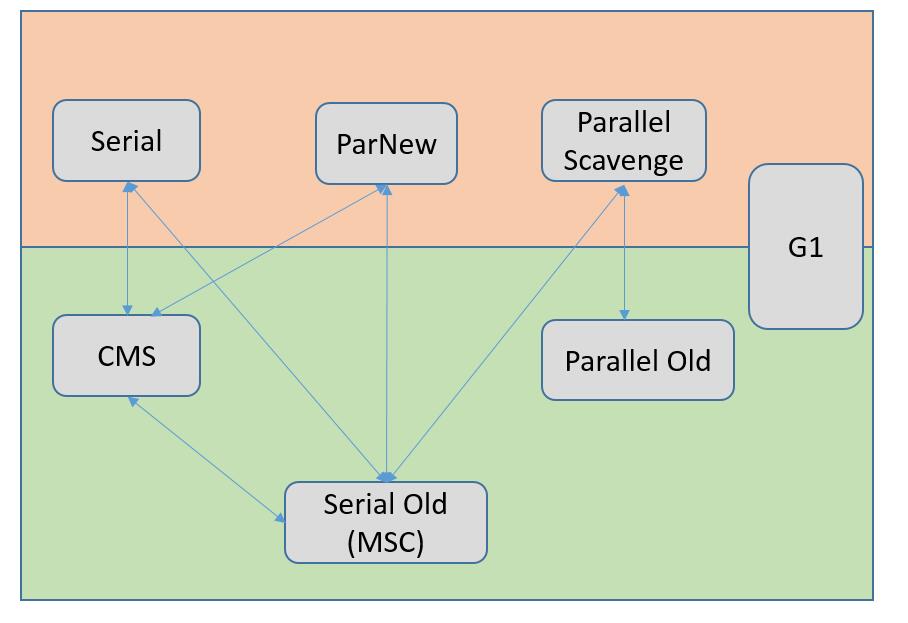
Serial GC算法:Serial Young GC + Serial Old GC (实际上它是全局范围的Full GC)
Parallel GC算法:Parallel Young GC + 非并行的PS MarkSweep GC / 并行的Parallel Old GC(这俩实际上也是全局范围的Full GC),选PS MarkSweep GC 还是 Parallel Old GC 由参数UseParallelOldGC来控制;
CMS算法:ParNew(Young)GC + CMS(Old)GC (piggyback on ParNew的结果/老生代存活下来的object只做记录,不做compaction)+ Full GC for CMS算法(应对核心的CMS GC在老年代给浮动垃圾预留的内存不足导致并发清除失败后full gc,开销很大);
Attaching to process ID 1014, please wait... Error attaching to process: sun.jvm.hotspot.debugger.DebuggerException: Can't attach symbolicator to the process sun.jvm.hotspot.debugger.DebuggerException: sun.jvm.hotspot.debugger.DebuggerException: Can't attach symbolicator to the process at sun.jvm.hotspot.debugger.bsd.BsdDebuggerLocal$BsdDebuggerLocalWorkerThread.execute(BsdDebuggerLocal.java:169) at sun.jvm.hotspot.debugger.bsd.BsdDebuggerLocal.attach(BsdDebuggerLocal.java:287) at sun.jvm.hotspot.HotSpotAgent.attachDebugger(HotSpotAgent.java:671) at sun.jvm.hotspot.HotSpotAgent.setupDebuggerDarwin(HotSpotAgent.java:659) at sun.jvm.hotspot.HotSpotAgent.setupDebugger(HotSpotAgent.java:341) at sun.jvm.hotspot.HotSpotAgent.go(HotSpotAgent.java:304) at sun.jvm.hotspot.HotSpotAgent.attach(HotSpotAgent.java:140) at sun.jvm.hotspot.tools.Tool.start(Tool.java:185) at sun.jvm.hotspot.tools.Tool.execute(Tool.java:118) at sun.jvm.hotspot.tools.JInfo.main(JInfo.java:138) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at sun.tools.jinfo.JInfo.runTool(JInfo.java:108) at sun.tools.jinfo.JInfo.main(JInfo.java:76) Caused by: sun.jvm.hotspot.debugger.DebuggerException: Can't attach symbolicator to the process at sun.jvm.hotspot.debugger.bsd.BsdDebuggerLocal.attach0(Native Method) at sun.jvm.hotspot.debugger.bsd.BsdDebuggerLocal.access$100(BsdDebuggerLocal.java:65) at sun.jvm.hotspot.debugger.bsd.BsdDebuggerLocal$1AttachTask.doit(BsdDebuggerLocal.java:278) at sun.jvm.hotspot.debugger.bsd.BsdDebuggerLocal$BsdDebuggerLocalWorkerThread.run(BsdDebuggerLocal.java:144)
> ~ jinfo --help Usage: jinfo [option] <pid> (to connect to running process) jinfo [option] <executable <core> (to connect to a core file) jinfo [option] [server_id@]<remote server IP or hostname> (to connect to remote debug server)
where <option> is one of: -flag <name> to print the value of the named VM flag -flag [+|-]<name> to enable or disable the named VM flag -flag <name>=<value> to set the named VM flag to the given value -flags to print VM flags -sysprops to print Java system properties <no option> to print both of the above -h | -help to print this help message
Definitions: <option> An option reported by the -options option <vmid> Virtual Machine Identifier. A vmid takes the following form: <lvmid>[@<hostname>[:<port>]] Where <lvmid> is the local vm identifier for the target Java virtual machine, typically a process id; <hostname> is the name of the host running the target Java virtual machine; and <port> is the port number for the rmiregistry on the target host. See the jvmstat documentation for a more complete description of the Virtual Machine Identifier. <lines> Number of samples between header lines. <interval> Sampling interval. The following forms are allowed: <n>["ms"|"s"] Where <n> is an integer and the suffix specifies the units as milliseconds("ms") or seconds("s"). The default units are "ms". <count> Number of samples to take before terminating. -J<flag> Pass <flag> directly to the runtime system. -? -h --help Prints this help message. -help Prints this help message.
"pool-1-thread-5" #16 prio=5 os_prio=31 tid=0x00007fe5e92ff800 nid=0x5703 waiting on condition [0x000070000887a000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x0000000795c2d4b0> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039) at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442) at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) // 之后省略
> ~ jstack 9527 // 前半部分忽略。只看最后 Found one Java-level deadlock: ============================= "pool-1-thread-2": waiting to lock monitor 0x00007fb7173f0758 (object 0x00000007955c0430, a java.lang.Integer), which is held by "pool-1-thread-1" "pool-1-thread-1": waiting to lock monitor 0x00007fb7173f0808 (object 0x00000007955c0440, a java.lang.Integer), which is held by "pool-1-thread-2"
Java stack information for the threads listed above: =================================================== "pool-1-thread-2": at com.richinfoai.umbrella.pipeline.publicFacility.utlis.Pair.lambda$main$1(Pair.java:43) - waiting to lock <0x00000007955c0430> (a java.lang.Integer) - locked <0x00000007955c0440> (a java.lang.Integer) at com.richinfoai.umbrella.pipeline.publicFacility.utlis.Pair$$Lambda$2/2110121908.run(Unknown Source) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) "pool-1-thread-1": at com.richinfoai.umbrella.pipeline.publicFacility.utlis.Pair.lambda$main$0(Pair.java:27) - waiting to lock <0x00000007955c0440> (a java.lang.Integer) - locked <0x00000007955c0430> (a java.lang.Integer) at com.richinfoai.umbrella.pipeline.publicFacility.utlis.Pair$$Lambda$1/204349222.run(Unknown Source) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
> ~ cat /proc/version Linux version 3.10.0-957.el7.x86_64 (mockbuild@kbuilder.bsys.centos.org) (gcc version 4.8.520150623 (Red Hat 4.8.5-36) (GCC) ) #1 SMP Thu Nov 823:39:32 UTC 2018
我们在java中开个线程,运行一个无限循环。
代码很简单:
1 2 3 4 5 6 7 8 9 10 11
publicclassInfinityLoop{
publicstaticvoidmain(String[] args){
inti=0; while (true){ System.out.println(i++); } }
> ~ java -cp . InfinityLoop > output.txt & > ~ jps 14889 InfinityLoop > ~ jstack 14889 // 前后省略没用的输出 "main" #1 prio=5 os_prio=0 tid=0x00007fe510009000 nid=0x3a2a runnable [0x00007fe519804000] java.lang.Thread.State: RUNNABLE at java.io.FileOutputStream.writeBytes(Native Method) at java.io.FileOutputStream.write(FileOutputStream.java:326) at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82) at java.io.BufferedOutputStream.flush(BufferedOutputStream.java:140) - locked <0x0000000080214020> (a java.io.BufferedOutputStream) at java.io.PrintStream.write(PrintStream.java:482) - locked <0x0000000080214000> (a java.io.PrintStream) at sun.nio.cs.StreamEncoder.writeBytes(StreamEncoder.java:221) at sun.nio.cs.StreamEncoder.implFlushBuffer(StreamEncoder.java:291) at sun.nio.cs.StreamEncoder.flushBuffer(StreamEncoder.java:104) - locked <0x0000000080214140> (a java.io.OutputStreamWriter) at java.io.OutputStreamWriter.flushBuffer(OutputStreamWriter.java:185) at java.io.PrintStream.write(PrintStream.java:527) - locked <0x0000000080214000> (a java.io.PrintStream) at java.io.PrintStream.print(PrintStream.java:597) at java.io.PrintStream.println(PrintStream.java:736) - locked <0x0000000080214000> (a java.io.PrintStream) at InfinityLoop.main(InfinityLoop.java:7)
"http-nio-8080-exec-1" #30 daemon prio=5 os_prio=31 tid=0x00007fb2a94c3000 nid=0x5c03 runnable [0x0000700009cae000] java.lang.Thread.State: RUNNABLE at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) at java.net.SocketInputStream.read(SocketInputStream.java:171) at java.net.SocketInputStream.read(SocketInputStream.java:141) at com.mysql.cj.protocol.ReadAheadInputStream.fill(ReadAheadInputStream.java:107) at com.mysql.cj.protocol.ReadAheadInputStream.readFromUnderlyingStreamIfNecessary(ReadAheadInputStream.java:150) at com.mysql.cj.protocol.ReadAheadInputStream.read(ReadAheadInputStream.java:180) - locked <0x0000000740afa5e0> (a com.mysql.cj.protocol.ReadAheadInputStream) at java.io.FilterInputStream.read(FilterInputStream.java:133) at com.mysql.cj.protocol.FullReadInputStream.readFully(FullReadInputStream.java:64) at com.mysql.cj.protocol.a.SimplePacketReader.readHeader(SimplePacketReader.java:63) at com.mysql.cj.protocol.a.SimplePacketReader.readHeader(SimplePacketReader.java:45) at com.mysql.cj.protocol.a.TimeTrackingPacketReader.readHeader(TimeTrackingPacketReader.java:52) at com.mysql.cj.protocol.a.TimeTrackingPacketReader.readHeader(TimeTrackingPacketReader.java:41) at com.mysql.cj.protocol.a.MultiPacketReader.readHeader(MultiPacketReader.java:54) at com.mysql.cj.protocol.a.MultiPacketReader.readHeader(MultiPacketReader.java:44) at com.mysql.cj.protocol.a.NativeProtocol.readMessage(NativeProtocol.java:549) at com.mysql.cj.protocol.a.NativeProtocol.checkErrorMessage(NativeProtocol.java:725) at com.mysql.cj.protocol.a.NativeProtocol.sendCommand(NativeProtocol.java:664) at com.mysql.cj.protocol.a.NativeProtocol.sendQueryPacket(NativeProtocol.java:979) at com.mysql.cj.protocol.a.NativeProtocol.sendQueryString(NativeProtocol.java:914) at com.mysql.cj.NativeSession.execSQL(NativeSession.java:1150) at com.mysql.cj.jdbc.ConnectionImpl.setAutoCommit(ConnectionImpl.java:2064) - locked <0x0000000740a6e9e8> (a com.mysql.cj.jdbc.ConnectionImpl) at com.zaxxer.hikari.pool.ProxyConnection.setAutoCommit(ProxyConnection.java:388) at com.zaxxer.hikari.pool.HikariProxyConnection.setAutoCommit(HikariProxyConnection.java) at org.hibernate.resource.jdbc.internal.AbstractLogicalConnectionImplementor.begin(AbstractLogicalConnectionImplementor.java:67) at org.hibernate.resource.jdbc.internal.LogicalConnectionManagedImpl.begin(LogicalConnectionManagedImpl.java:263) at org.hibernate.resource.transaction.backend.jdbc.internal.JdbcResourceLocalTransactionCoordinatorImpl$TransactionDriverControlImpl.begin(JdbcResourceLocalTransactionCoordinatorImpl.java:236) at org.hibernate.engine.transaction.internal.TransactionImpl.begin(TransactionImpl.java:80) at org.springframework.orm.jpa.vendor.HibernateJpaDialect.beginTransaction(HibernateJpaDialect.java:183) at org.springframework.orm.jpa.JpaTransactionManager.doBegin(JpaTransactionManager.java:401) at org.springframework.transaction.support.AbstractPlatformTransactionManager.getTransaction(AbstractPlatformTransactionManager.java:378) at org.springframework.transaction.interceptor.TransactionAspectSupport.createTransactionIfNecessary(TransactionAspectSupport.java:474) at org.springframework.transaction.interceptor.TransactionAspectSupport.invokeWithinTransaction(TransactionAspectSupport.java:289) at org.springframework.transaction.interceptor.TransactionInterceptor.invoke(TransactionInterceptor.java:98) at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186) at org.springframework.dao.support.PersistenceExceptionTranslationInterceptor.invoke(PersistenceExceptionTranslationInterceptor.java:139) at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186) at org.springframework.data.jpa.repository.support.CrudMethodMetadataPostProcessor$CrudMethodMetadataPopulatingMethodInterceptor.invoke(CrudMethodMetadataPostProcessor.java:135) at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186) at org.springframework.aop.interceptor.ExposeInvocationInterceptor.invoke(ExposeInvocationInterceptor.java:93) at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186) at org.springframework.data.repository.core.support.SurroundingTransactionDetectorMethodInterceptor.invoke(SurroundingTransactionDetectorMethodInterceptor.java:61) at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:186) at org.springframework.aop.framework.JdkDynamicAopProxy.invoke(JdkDynamicAopProxy.java:212) at com.sun.proxy.$Proxy79.save(Unknown Source) at com.lifeStory.study.test.TestThreadLongTimeRun.longTimeRun(TestThreadLongTimeRun.java:20) at com.lifeStory.study.controller.TestController.testThreadRunTooLong(TestController.java:26) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.springframework.web.method.support.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.java:189) at org.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:138) at org.springframework.web.servlet.mvc.method.annotation.ServletInvocableHandlerMethod.invokeAndHandle(ServletInvocableHandlerMethod.java:102) at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.invokeHandlerMethod(RequestMappingHandlerAdapter.java:895) at org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter.handleInternal(RequestMappingHandlerAdapter.java:800) at org.springframework.web.servlet.mvc.method.AbstractHandlerMethodAdapter.handle(AbstractHandlerMethodAdapter.java:87) at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:1038) at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:942) at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:1005) at org.springframework.web.servlet.FrameworkServlet.doGet(FrameworkServlet.java:897) at javax.servlet.http.HttpServlet.service(HttpServlet.java:634) at org.springframework.web.servlet.FrameworkServlet.service(FrameworkServlet.java:882) at javax.servlet.http.HttpServlet.service(HttpServlet.java:741) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:231) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.java:53) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) at org.springframework.web.filter.RequestContextFilter.doFilterInternal(RequestContextFilter.java:99) at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) at org.springframework.web.filter.FormContentFilter.doFilterInternal(FormContentFilter.java:92) at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) at org.springframework.web.filter.HiddenHttpMethodFilter.doFilterInternal(HiddenHttpMethodFilter.java:93) at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) at org.springframework.web.filter.CharacterEncodingFilter.doFilterInternal(CharacterEncodingFilter.java:200) at org.springframework.web.filter.OncePerRequestFilter.doFilter(OncePerRequestFilter.java:107) at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:193) at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:166) at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:199) at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:96) at org.apache.catalina.authenticator.AuthenticatorBase.invoke(AuthenticatorBase.java:490) at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:139) at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:92) at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:74) at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:343) at org.apache.coyote.http11.Http11Processor.service(Http11Processor.java:408) at org.apache.coyote.AbstractProcessorLight.process(AbstractProcessorLight.java:66) at org.apache.coyote.AbstractProtocol$ConnectionHandler.process(AbstractProtocol.java:834) at org.apache.tomcat.util.net.NioEndpoint$SocketProcessor.doRun(NioEndpoint.java:1417) at org.apache.tomcat.util.net.SocketProcessorBase.run(SocketProcessorBase.java:49) - locked <0x00000007a2ba9450> (a org.apache.tomcat.util.net.NioEndpoint$NioSocketWrapper) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61) at java.lang.Thread.run(Thread.java:748)
> ~ jmap -h Usage: jmap [option] <pid> (to connect to running process) jmap [option] <executable <core> (to connect to a core file) jmap [option] [server_id@]<remote server IP or hostname> (to connect to remote debug server)
where <option> is one of: <none> to print same info as Solaris pmap -heap to print java heap summary -histo[:live] to print histogram of java object heap; if the "live" suboption is specified, only count live objects -clstats to print class loader statistics -finalizerinfo to print information on objects awaiting finalization -dump:<dump-options> to dump java heap in hprof binary format dump-options: live dump only live objects; if not specified, all objects in the heap are dumped. format=b binary format file=<file> dump heap to <file> Example: jmap -dump:live,format=b,file=heap.bin <pid> -F force. Use with -dump:<dump-options> <pid> or -histo to force a heap dump or histogram when <pid> does not respond. The "live" suboption is not supported in this mode. -h | -help to print this help message -J<flag> to pass <flag> directly to the runtime system
Heap Usage: PS Young Generation Eden Space: capacity = 5767168 (5.5MB) used = 2119584 (2.021392822265625MB) free = 3647584 (3.478607177734375MB) 36.75259676846591% used From Space: capacity = 524288 (0.5MB) used = 0 (0.0MB) free = 524288 (0.5MB) 0.0% used To Space: capacity = 524288 (0.5MB) used = 0 (0.0MB) free = 524288 (0.5MB) 0.0% used PS Old Generation capacity = 14155776 (13.5MB) used = 0 (0.0MB) free = 14155776 (13.5MB) 0.0% used
2485 interned Strings occupying 181464 bytes.
> ~ jmap -dump:live,format=b,file=Desktop/heap.bin 24794 // 相对路径 Dumping heap to ~/Desktop/heap.bin ... Heap dump file created
> ~ jhat ~/Desktop/heap.bin Reading from ~/Desktop/heap.bin... Dump file created Sat Aug 17 17:40:52 CST 2019 Snapshot read, resolving... Resolving 15335 objects... Chasing references, expect 3 dots... Eliminating duplicate references... Snapshot resolved. Started HTTP server on port 7000 Server is ready.
-J<flag> Pass <flag> directly to the runtime system. For example, -J-mx512m to use a maximum heap size of 512MB -stack false: Turn off tracking object allocation call stack. -refs false: Turn off tracking of references to objects -port <port>: Set the port for the HTTP server. Defaults to 7000 -exclude <file>: Specify a file that lists data members that should be excluded from the reachableFrom query. -baseline <file>: Specify a baseline object dump. Objects in both heap dumps with the same ID and same class will be marked as not being "new". -debug <int>: Set debug level. 0: No debug output 1: Debug hprof file parsing 2: Debug hprof file parsing, no server -version Report version number -h|-help Print this help and exit <file> The file to read
For a dump file that contains multiple heap dumps, you may specify which dump in the file by appending "#<number>" to the file name, i.e. "foo.hprof#3".
All boolean options default to "true"
设置项很多,感觉比较有用的是-execlude和-bashline,其他的暂时没看出有多少用。
随便跑一下
1 2 3 4 5 6 7 8 9 10
> ~ jhat ~/Desktop/heap.bin Reading from /Users/mateng/Desktop/heap.bin... Dump file created Sat Aug 17 17:40:52 CST 2019 Snapshot read, resolving... Resolving 15335 objects... Chasing references, expect 3 dots... Eliminating duplicate references... Snapshot resolved. Started HTTP server on port 7000 Server is ready.
General options: --help show this help --jdkhome <path> path to Java(TM) 2 SDK, Standard Edition -J<jvm_option> pass <jvm_option> to JVM
--cp:p <classpath> prepend <classpath> to classpath --cp:a <classpath> append <classpath> to classpath Module reload options: --reload /path/to/module.jar install or reinstall a module JAR file
Core options: --laf <LaF classname> use given LookAndFeel class instead of the default --fontsize <size> set the base font size of the user interface, in points --locale <language[:country[:variant]]> use specified locale --userdir <path> use specified directory to store user settings --cachedir <path> use specified directory to store user cache, must be different from userdir --nosplash do not show the splash screen
# set -XX:MaxRAM to 70% of the cgroup limit docker run --rm -m 1g openjdk:8-jdk sh -c 'exec java -XX:MaxRAM=$(( $(cat /sys/fs/cgroup/memory/memory.limit_in_bytes) * 100 / 70 )) -XX:+PrintFlagsFinal -version'