

Sqoop异常

Sqoop异常
不定时更新
1. sqoop 命令格式
1 | sqoop export \ |
2. sqoop 并发引发的问题
前段时间在使用并发sqoop job的时候出现的问题,貌似是sqoop metastore出现了问题
在使用sqoop job --list时报错
1 | Caused by: java.sql.SQLException: User not found: SA |
出现问题后的的思路一直是寻找连接metastore,sqoop默认使用的是hsqldb,一种及其轻量的数据库,sqoop用其来存储一些sqoop job的中间状态.
而我用的是单机的sqoop 每个节点的sqoop都独立,没有配置sqoop server和统一的metastore,所以没有在sqoop.site.xml中配置.
每次启动sqoop 都会在用户的家目录即~/下生成.sqoop文件夹,并且在此文件夹下写一个名为metastore.db.script的文件,打开这个文件就发现了问题所在
sqoop job将所有的状态写进了这个文件中,在磁盘中存储,其中前几行是sqoop job自动生成的,之前报的错误就是因为此文件因为并发而损坏,文件中没有了内容,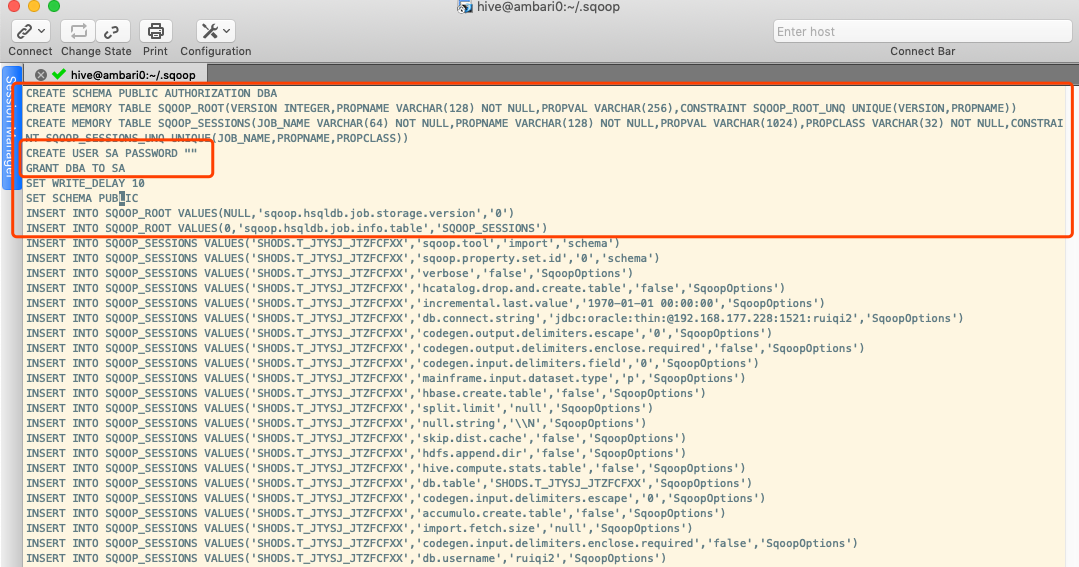
如果sqoop 命令异常或者文件损坏可以直接复制此内容到文件中来,这样可以保证sqoop job恢复
1 | CREATE SCHEMA PUBLIC AUTHORIZATION DBA |
而文件中的其他内容则是每个sqoop job的状态了,记录了一个sqoop job的详细信息,sqoop job -delete xxxx 就是在文件中将所有xxxx这个sqoop job的内容全部删除掉.
sqoop使用的默认数据库对于并发的支持不是很好,可以手动配置更改为其他数据库,例如mysql,但是这样就失去了sqoop自己提供的增量更新功能(提供更新列,自动根据更新列的值来做增量导入,实际上就是sqoop job所记录的状态和文件),自行实现sqoop job的功能代价太大,所以只好退而求其次,继续使用sqoop,同时在其他方面寻找改进方法.
另外,在遇到上述问题的时候,换了集群中的另一个节点时,又出现了第二个问题 Cannot restore missing job xxxx
每次创建sqoop job后执行时都会报错,sqoop job --list时也没有这个job,也暂时归结为并行造成的问题.取消并行后没有再遇到过.
3. sqoop import incremental
sqoop import中也提供了增量导入的功能
官方文档中关于sqoop import增量的部分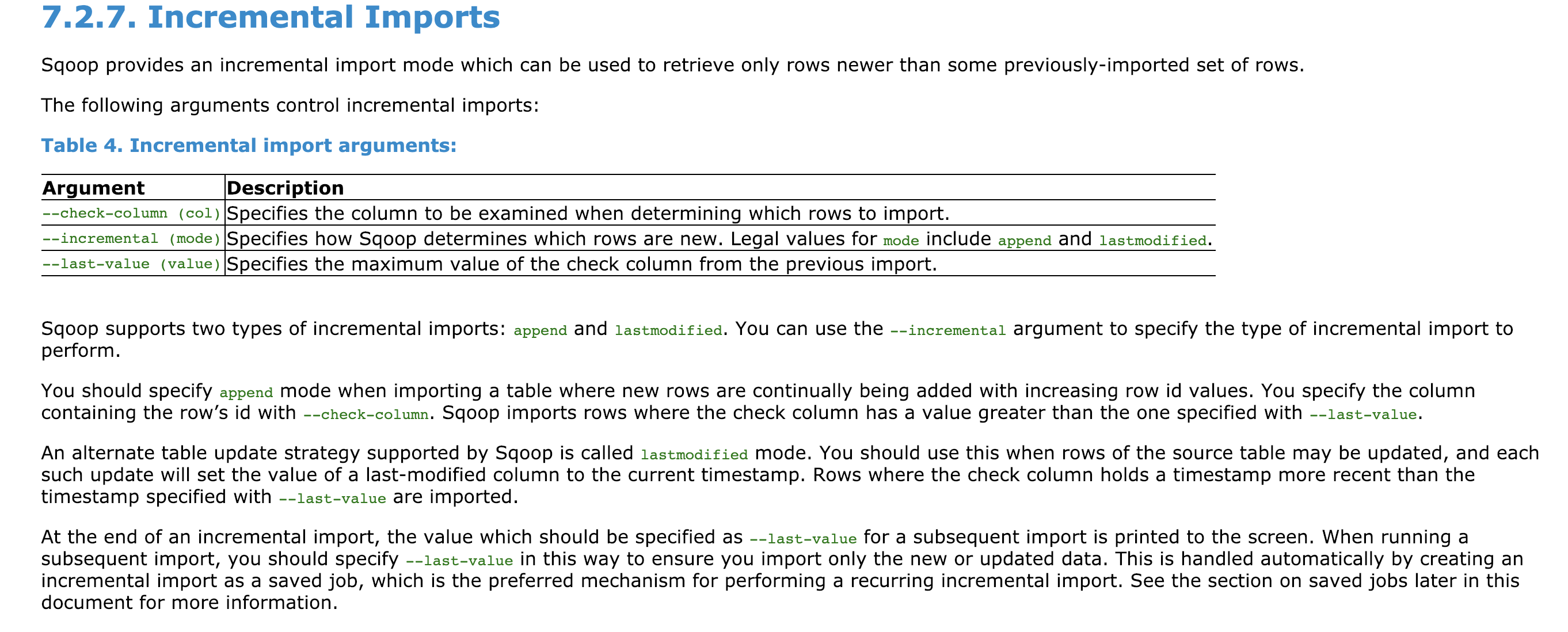
可以看到import 提供了三个参数来完成增量功能
1 | --incremental #指定增量的模式 |
比如指定id列实现增量导入
1 | --incremental-append \ |
或者指定时间列
1 | --incremental-lastmodified \ |
- 值得注意的是使用这种方式做增量导入的话,增量导入的数据中是包括lastValue的值在内的数据,也就是大于等于lastValue值的数据都会导入,而我的工作内容是更新更新时间做增量导入,无法实现实现类似id字段的自动增长和值的预估,使用此模式会导入重复数据.
所以我用到了sqoop import中的另外几个参数--query或者--where
4. sqoop import中的where和query
--query
query参数后边的SQL语句,需要注意:
- 一般不要用双引号,除非双引号里边包含单引号,使用双引号的话就不能再使用换行符了,双引号必须在同一行.
- SQL中的from后面的表明要写全,
XXX.xxx - 如果SQL中使用了where语句,后边必须有
$CONDITIONS条件,sqoop 运行的时候,看日志发现sqoop 会在这里插入(1=0)或(1=1)来控制这条语句的执行.外边使用双引号的话,$CONDITIONS 前边需要加反斜杠 即:$CONDITIONSsqoop import --quert "select * from XXX.xxx where \$CONDITIONS AND column > to_timestamp('1970-01-01 00:00:00','yyyy-MM-dd HH24:mi:ss')" - 参数和值一般一行一个,但是如果就像SQL语句一样,长的话可以在结尾使用反斜杠来换行
--query不能和--table一起使用
--where
使用--query的时候SQL语句里需要写select * xxx,看日志内容
1 | select * from ZAODS.T_ZAXT_BUREAU where (1 = 0) AND 'ACQUISTIONTIME' > to_timestamp('1970-01-01 00:00:00','yyyy-MM-dd HH24:mi:ss') |
考虑到是否会平添负担就放弃了.
而使用--where只需要提供增加的列名和界定值就可以了sqoop import --where "column > to_timestamp('1970-01-01 00:00:00','yyyy-MM-dd HH24:mi:ss')"
后来又有了新的需求:oracle中的大字段列(blob,clob)不做导入,因此选择使用--query,这样可以在SQL语句中选择某些列导入而忽略掉不合要求的列.